




Secuenciación del genoma del cáncer

Especial para Galenus Revista para los médicos de Puerto Rico
Adaptado de National Cancer Institute (NCI)
Centers for Disease Control and Prevention (CDC)
American Cancer Society (ACS)
La secuenciación del genoma del cáncer es un método de laboratorio bioquímico para la caracterización e identificación de las secuencias de ADN o ARN de las células cancerosas. A diferencia de la secuenciación del genoma completo, que se suele realizar a partir de células de sangre, de la saliva, de los epitelios o de los huesos, la del genoma del cáncer implica evaluar el tejido tumoral primario, el tejido normal adyacente o el del entorno tumoral, como las células estromales o las zonas metastásicas.
En 2006, se publicó el primer informe sobre el proceso de secuenciación del genoma del cáncer, con datos de 13,023 genes en 11 tumores de mama y 11 tumores colorrectales. El primer genoma de cáncer que se logró secuenciar fue de una leucemia mieloide aguda en 2008. El primer cáncer de mama se secuenció en 2009 y los primeros de pulmón y de próstata, en 2011. En la actualidad, gracias a los avances tecnológicos, se puede lograr una secuenciación en tiempos mucho más rápidos, lo que ha permitido también disminuir significativamente los costos. En algunos casos estos avances facilitan inclusive el estudio de la secuenciación del genoma completo y no solo del genoma del cáncer.
Almacenamiento de la información
A continuación, mencionamos 3 proyectos para documentar y almacenar la información:
- El Proyecto de Anatomía del Genoma del Cáncer (Cancer Genome Anatomy Project, CGAP). Se estableció en 1997 con el objetivo de documentar las secuencias de las transcripciones de ARN en las células tumorales;
- El Proyecto Genoma del Cáncer, Instituto Sanger, que desde el 2020 es Wellcome Sanger Institute, se centró desde 2005 en la secuenciación del ADN. Publicó una lista de genes implicados en cáncer; y
- El Consorcio Internacional del Genoma del Cáncer (International Cancer Genome Consortium, ICGC) se fundó en 2007 con el objetivo de integrar los datos genómicos, transcriptómicos y epigenéticos disponibles de diferentes grupos de investigación. Cuenta con datos de más de 25 mil genomas de más de 50 distintos tumores.
Impacto y relevancia clínica
La mayoría de los cánceres tienen varios subtipos y, además, hay diferencias entre un subtipo de cáncer en un individuo y en otro. La secuenciación del genoma del cáncer permite a los médicos identificar en algunos casos los cambios específicos y únicos que ha sufrido un paciente para desarrollar su cáncer, para así poder emprender una estrategia terapéutica personalizada.
Una gran contribución ha sido la evaluación citogenética, por ejemplo en la leucemia mieloide aguda (LMA). Se han estudiado facciones celulares caracterizadas por cambios mutacionales comunes para ilustrar la heterogeneidad de un determinado tumor antes y después del tratamiento.
Las facciones celulares solo se han podido definir gracias a la secuenciación del genoma del cáncer, lo que confirma la importancia de contar con la información de la secuenciación debido a la complejidad y heterogeneidad de un tumor individualmente.
Proyectos integrales de genómica del cáncer
Los 2 principales proyectos centrados en la caracteri-zación completa y secuenciación del cáncer son:
- El Proyecto del Genoma del Cáncer (CGP), con sede en el Instituto Wellcome Trust Sanger. Su objetivo es identificar variantes de secuencia y mutaciones críticas en el desarrollo de los cánceres. Los resultados se almacenan en la base de datos de cáncer COSMIC que también incluye datos mutacionales publicados en la literatura científica;
- El Atlas del Genoma del Cáncer (TCGA), patrocinado por el Instituto Nacional del Cáncer (NCI) y el Instituto Nacional de Investigación del Genoma Humano (NHGRI) estudia la secuenciación del genoma del cáncer. Cada tipo de cáncer se somete a un análisis genómico exhaustivo. La información está disponible de forma gratuita a través de su portal de datos.
Avances en tecnología de secuenciación
La tecnología de secuenciación ha continuado en constante evolución, habiendo avanzado por distintas “generaciones” técnicas. Las principales plataformas incluyen la secuenciación en tiempo real de una molécula, la secuenciación de nanoporos y por semiconductores.
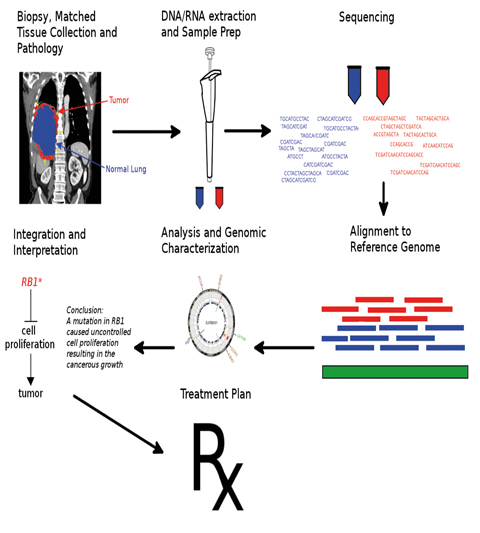
Análisis de los datos
En el estudio de los genomas del cáncer las lecturas se ensamblan y alinean con el genoma humano de referencia. Como inclusive las células no cancerosas acumulan mutaciones somáticas, es necesario comparar la secuencia tumoral con un tejido normal para determinar las mutaciones exclusivas del cáncer. En algunos tipos de cáncer, como en la leucemia, no resulta práctico comparar la muestra de cáncer con un tejido normal, por lo que se debe utilizar un tejido no canceroso diferente.
Un objetivo importante de la secuenciación de un genoma de cáncer es identificar las mutaciones impulsoras que destacan los cambios genéticos que aumentan la tasa de mutación celular y pueden conducir a una evolución tumoral más rápida y a metástasis. Se estima que un tumor medio tiene unas 80 mutaciones somáticas, de las que se espera que menos de 15 sean impulsoras.
Se vienen desarrollando y perfeccionando diferentes softwares con el objetivo de identificar las variantes de nucleótido único, las que guarden relación directa con la transformación celular y el desarrollo de tumores.
Un análisis genómico personal requiere una mayor caracterización funcional de los genes mutantes detectados. Este análisis puede utilizarse para hacer recomendaciones de tratamiento farmacológico.
Comentario
La secuenciación del genoma del cáncer puede utilizarse para proporcionar información clínicamente relevante en pacientes con tumores, inclusive aquellos raros o novedosos. Es un campo que está en continua evolución y en el que los buenos resultados no siempre están garantizados. Poder traducir la información de la secuencia a un plan de tratamiento clínico es algo altamente complejo que requiere de un equipo multidisciplinario.
Referencias
- Pleasance ED. A small-cell lung cancer genome with complex signatures of tobacco exposure. Nature. 2009. 463 (7278): 184-90.
- Pleasance ED. A comprehensive catalogue of somatic mutations from a human cancer genome. Nature. 2009. 463 (7278): 191-6.
- Berger MF. The genomic complexity of primary human prostate cancer. Nature 470, 2011 (7333): 214-20.
- Ding L. Clonal evolution in relapsed acute myeloid leukaemia revealed by whole-genome sequencing. Nature. 2012. 481:506-510.
- Wood LD. The genomic landscapes of human breast and colorectal cancers. Science. 2007. 318 (5853): 8-9.
- Bailey MH, Tokheim C, et al (2018) Comprehensive characterization of cancer driver genes and mutations. Cell 173(2):371–385.
- Cosmic. Catalogue of somatic mutations in cancer. https://cancer.sanger.ac.uk/cosmic Published January 16, 2017.



